Does the thought of VMWare snapshots for Exchange 2013 make you cringe? If so, we are much alike and your concern probably stems from unpleasant experiences you’ve had in the past. Exchange 2010 SP1 began the “healing” process between Exchange and VMWare however much of the stigma remains implanted in the heads of Exchange administrators.
Fear not! As the technologies continue to bridge together they grow more compatible and can thrive together with a small amount of work and monitoring. First, lets talk about the problems Veeam can cause; you will likely see these errors:
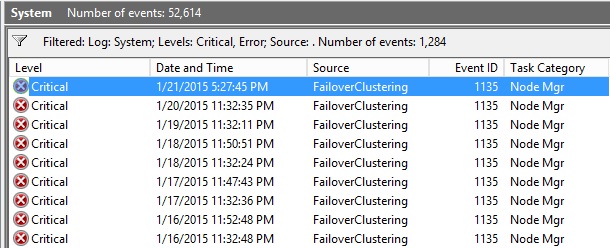
FailoverClustering – Event ID: 1135 – Cluster node ‘SERVER’ was removed from the active failover cluster membership. The Cluster service on this node may have stopped. This could also be due to the node having lost communication with other active nodes in the failover cluster.
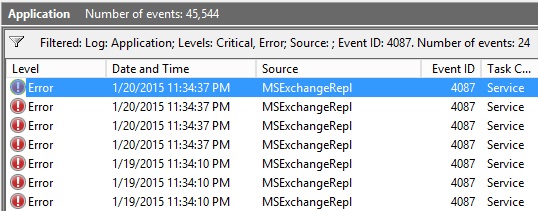
MSExchangeRepl – Event ID: 4087 – Failed to move active database ‘NAME’ from server ‘SERVER’. Move comment: None specified.
Error: An error occurred while attempting a cluster operation. Error: Cluster API failed: “ClusterRegSetValue() failed with 0x6be. Error: The remote procedure call failed”
The problem is the very way that Veeam operates since it must necessarily “freeze” the guest node to complete the snapshot. This isn’t to say that Veeam isn’t following Microsoft Best-Practices. Veeam DOES in fact initialize VSS to take an Exchange-Aware snapshot so all is well with the backups and logs are being correctly truncated. However, during the snapshot period, the Cluster will detect a short outage and attempt to fail the databases which could set off some other failures as shown above.
What we have to do is change the Cluster settings to be more forgiving of these short “freezes”. The end result is an error-free backup and failover detection that is a little more forgiving of slight network outages or slower server responses. From any server in the DAG, open the Command-Prompt and enter the following text:
cluster /cluster:<DAGNAME> /prop SameSubnetDelay=2000:DWORD
cluster /cluster:<DAGNAME> /prop CrossSubnetDelay=4000:DWORD
cluster /cluster:<DAGNAME> /prop CrossSubnetThreshold=10:DWORD
cluster /cluster:<DAGNAME> /prop SameSubnetThreshold=10:DWORD
These settings are recommended by Veeam to force the cluster to allow for twice the amount of delay for the cluster’s heartbeat and network delay. The numbers look high but they really aren’t. 4,000 milliseconds is 4 seconds and for most companies a 4-second heartbeat tolerance will probably be just fine. I personally think the default second of 1,000 milliseconds is probably too low anyway. The other settings …SubnetThreshold is the failed heartbeat tolerance. By increasing this you also increase the failure tolerances before a fail-over automatically occurs. The default setting is 5 so by doubling that, we decrease the potential for an unplanned failover due to “glitches” with the network or short “freezes” like those instigated with products like Veeam.
These problems should instantly quieten down the Event Logs on your server if Veeam or anther product forces your Exchange Servers to “pause” momentarily for whatever reason. Moreover, if your Exchange environment is not closely being monitored then you may want to make these changes in order to make your DAG more stable during short unplanned problems with the network or perhaps host machines.

